Hi Community!
This is our progress report from month 4. We're proud of what we have learned and achieved so far, we've worked hard to make this accessible in this longread and also share our struggles. We would love you to take a look, read and share feedback or questions!
Project Update
First, a short description of our project: We are prototyping a survey platform that rewards respondents automatically upon filling in a survey using the Interledger specification. Survey-data will be stored in linked data format and users can copy the data on their own personal data storage: a SolidPod. In that way researchers can use citizen science as a way to collect data and contribute to environmental health research.
In this progress update we'll cover our findings on the technical part of payments (a reward collection service), about surveys including Linked Data, Solid Pods and reusable data/surveys, and also share what we learned from interviewing researchers about payments and surveys. Because we value privacy by design and based on user experience and technical considerations we have decided to change some elements which we'll dive deeper into below.
Highlight: Reward collection service: Cash-link
First we want to highlight a service we are building we think is very interesting: We 'll separate the server of the payments from the survey server so after filling in a survey a respondent is redirected to a screen where a respondent can fill in a payment pointer and get a reward. This will act as a reward collection service that's reusable.
We think the idea of a 'reward collection service' where you can fill in your payment pointer and get rewarded is a great abstraction of the concept of value transfer with payment pointers and will provide bigger value for the interledger community. Also this contributes to privacy by design of the POC.
Watch a short demo of the cash-link service below including the researcher setting up the survey and setting the payments, and the respondent filling in the survey and using the cash-link!
(note in this phase we used Typeform for the actual survey questions)
Cash-link: Privacy by design
In the context of surveys, the researcher can choose to use their own identifiers for identifying individuals responding to the survey. The survey system itself uses an unique token for each respondent, which might include an internal identifier used for linking responses to individuals by the researcher. After submitting the survey, the respondent can enter a payment pointer to receive a reward. To avoid linking payment pointers to individual survey responses, potentially creating a privacy breach, a strong separation of the identifiers and the payment pointer is needed. At the same time the system must be resilient to fraud and create an audit trail.
That's why we're building a separate service for handling the payout process called Cash-link. Both the survey tool and the payout service run as separate services and when communicating with each other, they encrypt and authenticate their communication mutually with an asymmetric keypair.
On response submission, the survey service generates an encrypted token that represents a certain value, and encodes it into a URL. This URL sends the user to the payment service, which decodes the encrypted token and prompts the user for their payment pointer. This architecture prevents the Survey service from knowing which payment pointer is linked to a certain survey response. Though for the respondent the separation is barely noticeable; the respondent only reveals the payment pointer to the payment service.
Both the survey service and the payment service keep their own logfiles and they log a unique payment identifier per transaction, making an audit possible, but only after explicitly combining the logfiles from two different services. The researcher only has access to the single-use identifier in the link and may combine it with their own identifiers without any risk of correlation to identifiers like the payment pointer. The survey results themselves are of course accessible to the researchers, but the participant may store and reuse the data when they want to.
This Cash-link service is a standalone typescript node server designed to be re-used in other projects and it is fully open source. The tokens themselves can be generated by any library that supports JWE (JSON Web Encryption), which means that many existing frameworks and languages have tools available to create these tokens. A reference implementation in typescript is also available here.
Progress on objectives
POC
The survey tool aims to enable researchers to gain data about environmental health topics with the help of citizens who are rewarded for filling in surveys using the Interledger specification. We'll dig deeper into the details of this POC in the key deliverables. Also we contacted researchers to interact with them about this topic. We describe our learnings from these interviews about citizen science and payments in the communications and marketing paragraph. In the section below we'll share some high-over learnings on our goals in payments, surveys, Solid Pods and privacy.
Lessons learned with Uphold and Interledger
Our project is a bit different from most of the other projects in this community, as our concept involves sending one-off payments to payment pointers from a server, instead of sending payment streams to payment pointers from a browser.
We've come a long way building the payment server and enabling setting payments for surveys, but found out that there is a missing last puzzle piece since Uphold (and all of the other wallets) currently does not support Interledger Payments in it's API for sending payments. We have finished the reward collections service based on the current integration we have built with Uphold and connected this with the survey server. We'll continue as planned, but the payment itself will not yet be able to be done using the interledger protocol. If the ability to make one-off payments becomes available in the Uphold API in the remaining time of our project we will integrate this. We're also looking for other solutions. We're excited about Rafiki (an all-in-one Solution for Interledger Wallets) and will keep track of Rafiki's updates.
Towards reusable surveys & survey responses
We included Linked Data and Solid in our project as a way to enable citizens to copy their survey data on their own SolidPods. It resonates with the principles of standardized FAIR data: Findable, Accessible, Interoperable, and Reusable.
Boths surveys and survey responses are not standardized a lot, at least not technically. This means that the questions themselves have vastly different representations, and the same goes for the answers. Reusable data and surveys are more likely to be involved in payments because they become more valuable. In the next two sections, we'll discuss our learnings, why it makes sense to standardize both responses and questions, and how this could be realized.
Reusable responses
Since many surveys describe personal information, it makes sense, as a respondent, to have a way of storing the information you filled in in a place that you control. Making this possible enables a few nice use cases.
Previously entered response data could be usable while filling in new surveys. This could result in a UX similar to auto-filling forms, but far more powerful and rich than browsers currently support.
Standardized survey responses could also be used to gather insights into your own personal information. For example, filling in a survey about how your shortness of breath linked to air pollution has been today could be used in a different app to make a graph that visualises how your shortness of breath has progressed over the months for personal insight.
Achieving something like this requires a high degree of standardization in both the surveys and the responses. The survey and its questions should provide information about:
The question itself. This is required in all survey questions, of course.
The required datatype of the response, such as 'string', or 'datetime' or some 'enumeration'.
A (link to a) semantic definition of the property being described. This is a bit more obscure: all pieces of linked data use links, instead of keys, to describe the relation between some resource and its property. For example, a normal resource might have a 'birthdate', while in linked data, we'd use 'https://schema.org/birthDate'. This semantic definition makes things easier to share, because it prevents misinterpretation. Links remove ambiguity.
A query description. This is even more obscure, but perhaps the most interesting. A query description means describing how a piece of information can be retrieved. Perhaps a question in a survey will want to know what your payment pointer is. If a piece of software wants to auto-fill this field, it needs to know where it can find your payment pointer.
How to achieve these technical goals? Well, the inventor of the World Wide Web (sir Tim Berners-Lee) started an initiative called Solid, which is a set of specifications that aim to help users get control over their data, and improve interoperability between web applications. We wanted to work in this direction.
However, achieving the high degree of survey response interoperability seems a bit too ambitious, at this moment.
Firstly, the problems regarding data discoverability and data types are not yet solved for Solid. There are (at least) two competing standards for describing datatype shapes (SHACL and SHEX).
The Shape Trees specification aims to solve some of these problems, but implementing this (still in draft) spec in our infrastructure would be too time consuming at the moment. The specification is very interesting, but is also not stable yet and quite complex. It requires having a SHEX parser, working with dynamic filenames, supporting file systems and more.
Some of us are working on a specification that has some similarities to Solid, called Atomic Data. It can be converted to RDF, but it is a bit more constrained. These constraints allow for some solutions that could really help realizing a higher degree of standardization in surveys. The Atomic Schema spec could standardize the surveys and responses, and Atomic Paths enable the query descriptions. If you'd like to contribute to a potential solution, please check out the issue for Atomic Data Surveys.
Reusable surveys: context matters
If the answers based on a survey are stored in a personal data storage, these become reusable from a machine point of view. However also the context of the survey matters: if I am a respondent and rate my shortness of breath linked to air pollution (an environmental health topic) then this answer can't be re-used one on one on a Covid-related questionnaire on shortness of breath for example: people may asses their shortness of breath differently in those different contexts. To become a valuable questionnaire the context needs to become insightful too.
During the interviews with researchers it became clear that there are some projects running that try to standardize the surveys and to describe their context in a standardized way, but none of those initiatives formalize their work into ontologies that are structured enough to translate them into SHACL, SHEX or shape trees. Right now, survey tools use different kinds of representations and models, and these can often not be shared between them. To be reusable in practice, this gap needs to be bridged too. One possible way forward is to extend an existing project like Data Documentation Initiative (DDI, https://ddialliance.org/) with formalized descriptions of the data.
Privacy, surveys, data allocation and Solid pods
One of the core principles in privacy is that no more personal data is collected, stored, accessed, used and exchanged then is needed for the goal it serves. In the context of surveys the goals and with it the need for processing data hugely differs from use case to use case. To name some:
In some cases the researcher only needs the responses to one survey, in other cases the researcher needs to link the results from the survey with different data sources. To do so, the researcher needs some kind of identifier to link the data.
In some use cases, changing the answers after the data is once submitted will break the research, in other use cases updating the answers is part of the research.
Often, but not always, the researcher will 'normalize' the data: create a copy of the data that is cleared from errors and can be used for statistical analysis. This copy diverts from the original responses.
Such differences result in different levels of control of the respondent over the submitted data. The basic assumption of Solid pods: 'it is my data, so I need control over it', is not that straightforward in the context of surveys. Still there are some use cases in the context of surveys where Solid pods may have additional value:
To create a personal copy of the responses that can be used for own insight, possibly over time and own analysis.
To pre-fill the answers on similar questions in subsequent surveys.
To share the answers with different researchers for different research.
All these use cases demand full control of the respondent over the data stored, so in these use cases, Solid pods are a powerful tool. The more reusable the data is stored on the Solid pod, the better these use cases can be covered.
Key activities
POC survey
During our project we are researching potential uses, which mainly involves interviewing researchers. These researchers are generally quite familiar with survey tools, which helped us to identify potential areas for improvement.
We designed a user interface for both the researchers and for the respondents. While building the payments server we also focussed on the UI and UX while iterating in Figma in new designs and user flows constantly.
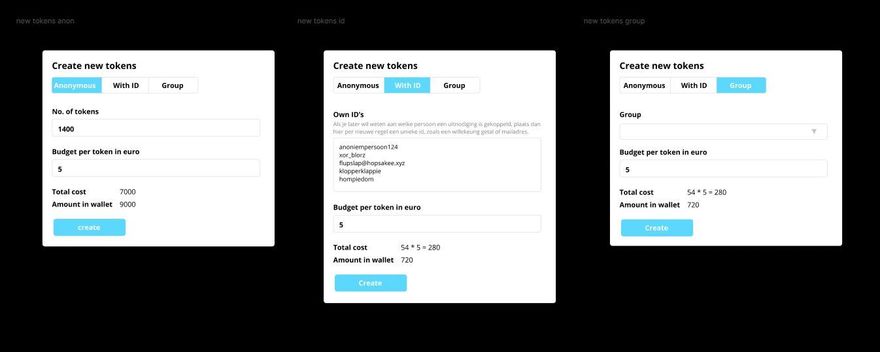
We’ve built the software for generating and validating the tokens for survey invites, which is basically an implementation of the designs shown above. This means we can create a survey, set payment conditions and generate + validate tokens.
The next step for us was building the Cash-Link service mentioned earlier, which is a standalone web service that turns links into cash. Open a link, enter your payment pointer, and receive funds. We've built this as a typescript application in the Next.js framework. The source code is available on Gitlab.
We've currently used Typeform for creating the questions in the survey. In the following weeks, we will build our own question management tool (i.e. the survey generator). After that, we'll build the response management tool (i.e. the analytics software). We'll also add the export feature for both surveys and responses, which means these can be re-used as RDF data in Solid pods.
Changes: accounts
We have decided we will not use accounts/login for respondents. We want to collect as little data as possible from respondents from a privacy by design view. Having an account is not necessary for respondents. We prevent sleeping accounts with passwords and private data.
Also this enables respondents to start right away with the survey, instead of having to create an account first, which enhances the user friendliness and user flow and prevents road blocks. This is also feedback from the researchers we interviewed.
Changes: invitations
Our initial thought was we would send emails with invite-urls to respondents via the survey platform. We have changed this in enabling the researcher to upload respondent's id's (like mail addresses or other id's) and generate a list of tokens linked to those id's. The researcher can export this list, and use it to send the invite-urls themselves. After the invite-urls have been sent, the researcher can see on the platform which tokens weren't used yet, export a list of these and send a reminder themselves. We don't send mass-mail invites via the platform. It offers the researcher the opportunity to use other communication tools apart from email (like platforms or apps). Also a researcher can upload other id's (numbers related to their own database) or anonymized id's which contributes to privacy. Mass emailing from a platform can lead to being blocked by spam filters. Also setting upa mass invite tool which provides good user experience like custom messages etc. is complex to add to other activities in the restricted project time and work out properly.
Communications and marketing
We have contacted several scientists from organisations and projects that work with citizen science and environmental health to inform them about interledger and learn how they work, and to ask what they think of this service and look at possible use cases it can be applied to and also dug deeper into the topic by doing deskresearch. Citizen science involves many different sides stretching from communication, data, ux and assembling & organising panels and participation.
Some organisations and projects we learned from:
Cities Health project, an citizen science project in Europe focussing on environmental science and epidemiology by tackling health issues that concern them.
Alterra (Wageningen Environmental Research) an organisation that contributes by qualified and independent research to the realisation of a high quality and sustainable green living environment.
ODISSEI (Open Data Infrastructure for Social Science and Economic Innovations) is the national research infrastructure for the social sciences in the Netherlands.
Mass online Experiments in Social Sciences (Utrecht University) which also include payment and survey related topics.
Developers of a Dutch participant recruitment platform from the Vrije Universiteit Amsterdam who are developing an affordable, sustainable, and secure online participant/annotator recruitment platform for Netherlands-based academic researchers. The reason they develop this platform, although there are already international online platforms for this, are obstacles in cultural aspects, GDPR and data quality.
These interactions led to the following insights:
Payments serving multiple goals: incentivizing, reimbursing costs, diversifying research population and gamification
Since payments are a main part of our project we researched and learned that reimbursing and paying citizens to participate in citizen science could apply to different topics:
Sign up bonus: a lot of survey platforms use this as a way to attract potential respondents
Thanking citizens for participating with a small coupon. Sometimes when also personal health data is involved legal obligations don't allow you or restrict you to incentivize people to share this data.
Reimbursing for travelling costs and other practical issues like electricity costs for devices like devices that measure air-pollution.
Payments as a form of diversifying the research population because some groups of citizens are more likely to participate, and using payments could result in better representativity of population and data.
Dynamic and variable rewards. In the field of social science for example gamification is used for social experiments. These games often rely on a reward that is dependent on the performance in the game.
Participation: it can be hard to get enough respondents because people are overwhelmed by information-society. Payments could help get respondents to participate. An argument against this is only a certain type of respondent would be incentivized making the respondents pool and data not representative.
Donation: participants that are not incentivized by payments (for example because they earn enough money) could still be willing to participate if the amount is donated to a certain goal (e.g. charity), thereby broadening the potential target audience.
We learned that in health and nature related topics most of the time there are enough participants because of an intrinsic motivation. In social sciences it was harder to find participants. Pools of students are sometimes created by making participating in a research a mandatory part of their education.
We found out asking small questions regularly instead of a lot of questions once is also an upcoming phenomenon.
Cultural aspects influence how to perform citizen science too: Although international online platforms exist to recruit human participants (e.g., MTurk, Prolific, Cint, Figure8), these are unusable for research bound to the Dutch linguistic and/or cultural context, have GDPR issues (data is possibly stored on servers outside Europe) and data quality issues.
Platforms we found interesting are for example https://www.iedereenwetenschapper.be/ (translated: everybody is a scientist) where citizen science is used for research in climate change, historical research etc.
Also https://www.otree.org/ a software platform for behavioral experiments got our attention because they have an example with payments: https://otree-more-demos.herokuapp.com/demo/randomize_stimuli
We also found some very interesting experimental use cases.
Experimental use case: publishing scientific papers
Publication of scientific papers that are peer reviewed cost money to access. Open science is the practice of science in such a way that others can collaborate and contribute, where research data are freely available, under terms that enable reuse, redistribution and reproduction of the research and its underlying data and methods. Publishing scientific papers combined with Web Monetization could be an interesting use case to investigate.
Experimental use case: paid devices and sensors as a sustainable form of environmental research
Deskresearch put us on the path of a project that installs 20.000 weather stations in Africa.
Experience learns that if the project funding stops the infrastructure also stops. The solution is to make the project self-sustaining. This can be done by selling the data. With the proceeds you can maintain the network, let it grow and expand all over Africa.
A customer could be insurance companies that can use the data to verify a claim of loss of crops by using the data from the weather station without having to travel huge distances to each field to check and assess the claim.
When you start to think about the possibilities with SolidPods connected to weather stations then even more innovation is possible.
What's next?
Survey generator / builder and response analytics software
Export survey and response data as RDF (compatible with Solid Pod)
Keep track of Rafiki's updates
Blogpost about interledger and Solid, privacy and citizen science
Finish Privacy Impact Analysis and accessible blog about privacy in the project.
Interview a researcher that has mapped 200+ citizen science projects in the Netherlands
Keep researchers updated about our project
What community support would benefit your project?
We would love to hear from the community and receive feedback on our progress so far. If your project also somehow involves the topics mentioned above we would like to share thoughts and learnings. Especially topics like Rafiki possible implementations, Linked data and surveys!
Additional comments
When saving your own reports to the community forum, you can convert it to Markdown using this tool: https://euangoddard.github.io/clipboard2markdown/)





Top comments (7)
So much to learn here! Thanks for the effort explaining this in-depth report 🙏🙏🙏
Thank you Radhy!
@gijs this is stellar report! 🏅 I really appreciate the level of detail you've shared and enjoyed your ideas around incentivizing, reimbursing costs etc.
@Erika Thank you for your nice words! :) I will pass them on to our team :)
I just saw the Markdown Converter! Nice. Also I think Rafiki we help connect ILP to this work better. One time payments is going to be a revolution in this space.
This is an excellent report!
Thank you Chris!