This is an update on the automatic captioning proof-of-concept that we have been working on for the past couple months, as part of our grant for the Waasabi live event framework.
Below you can read about our motivations, the progress we have made, sprinkled with some early demos and examples, as well as some of the future plans. This is going to be a long post, feel free to jump around to the parts you care about.
On Transcripts
The earliest motivation of this work was born out of our dedication to inclusive and accessible events at RustFest, and had nothing to do with automated captions. All our events in the past years - online, or in-person - have been live closed-captioned by a professional stenographer. These live captions have made our content accessible for disabled people and also attendees who were not native English-speakers (which, as you'd imagine for Europe's largest Rust conference meant most participants).
Our live captioners also produced a transcript of every talk, that we were hoping to put to good use eventually — but in reality for the longest part were just collecting dust tucked away in a GitHub repository. RustFest Global now publishes all talk transcripts on the individual session pages, which was an improvement in some ways (searchability, SEO), but at the end of the day this was still very far from the ideal user experience. Throughout the years we slowly recognized what we truly needed was a more direct connection between the audio, video and text.
The thing our transcripts were missing dearly is the timings. The difference between transcripts and captions is what's called "timecoding" in industry terms: annotating the transcript with time codes that correspond to precise timecodes of the original recording. We always made sure to allocate funds for captioning from the conference budget, but being a small community event it was never easy to justify the extra costs of hiring a professional timecoding service after the event already ended.
YouTube getting better at captioning has alleviated the pressing need for getting our transcripts in order (more on this later), but we never truly given up on making this happen without the big G watching over our shoulders.
Closed captions for conferences, today
A small intermission before we move on. There's no question whether paying (often thousands of dollars) for a professional live captioner's time is worth it, when it comes to the accessibility of a paid event — that is what conference budgets are for. That said (and this was true even before the Coronavirus-pandemic) flying a captioner and their equipment to the conference is not a cost that is worth it — for the organizers, and the captioner alike. Why yank someone out of their cozy home or office, away from their family, hurl them halfway across the planet amidst a climate crisis just to... spend a day listening to someone talking into a microphone and transcribing what they said all the same? Right?!
Well, of course it's not this easy, as latency becomes an issue. Live captions will have some inherent latency — even the fastest captioner needs to listen to, understand, and type up what is being said — but when you add VOIP, internet roundtrip latencies and other factors, on occasion, captions would sometimes become significantly delayed (in the tens-of-seconds range) which may very well become confusing, especially for abled people who can hear and understand the audio of the presentation.
As a weird twist, online conferences often exhibit the polar opposite of this issue! Due to inherent properties of the widely deployed HLS and similar streaming technologies, the so called "glass-to-glass" latency of live streams is frequently 15-30s or even higher. This forces event organizers to choose between two bad choices: stick to the traditional method of putting captions onto the streamed out video (and accepting the significant latency inherent to the work of a remote captioner), or push the captions directly into the clients on a separate channel, which risks desynchronization and potentially even captions arriving before the live stream catches up!
At RustFest we are not really fans of "the lesser of two evils"-sort of ultimatums so we had to come up with a plan. And so we did.
The Waasabi Captions PoC
Disclaimer: This is a proof-of-concept. This is not ready-to-use software, but a couple of focused experiments to establish the feasibility of this endeavor. The experiments showed quite promising results, and we intend to publish the current work as well as continue to grow this project into software that could be used by anyone (with or without Waasabi itself). If you like the direction please consider supporting the project or even contributing to the work (find the relevant links at the end of the article).
In keeping with the spirit of Waasabi, the goal for this captioning component was to provide a live captioning solution for event organizers that is completely independent of external services and API providers. Our focus is on small, largely free community events, organized primarily by enthusiasts, and not to cater for enterprise events and large, multiple-thousands-strong commercial conferences.

It was clear that we should be looking for a solution in the booming machine learning space, and importantly, one that used free & open source software and royalty-free training data, available to anyone. This proof-of-concept integrates Mozilla's DeepSpeech project for machine-learning-assisted speech-to-text processing, which itself is built on models generated from open training data using the industry-standard open source TensorFlow framework.
Testdriving the default model
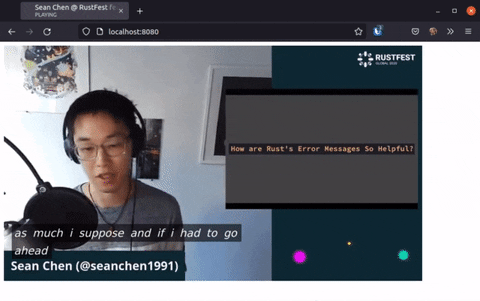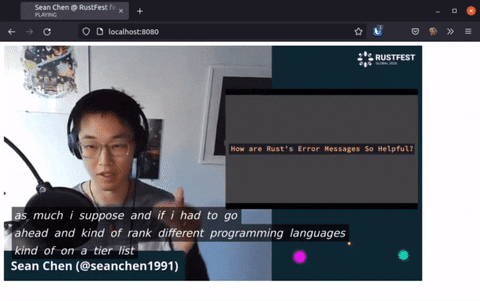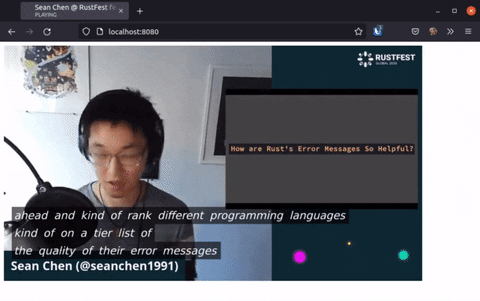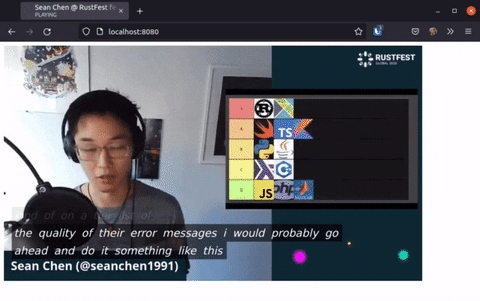
The experiments below are using Sean Chen's talk on Rust Error Messages from last year's online RustFest Global conference as an input. Sean is a fairly eloquent native English speaker so we are playing easymode here, but for a proof of concept this serves as a sufficient foundation.
First we fed the unmodified talk audio into DeepSpeech's pre-trained model — the result of this was already really interesting!
As part of this exploratory research we have created several, relatively simple JavaScript tools to aid us in the evaluation. One of these tools takes DeepSpeech's output and tries to cross-reference it with our existing transcript for the same audio. Another tool is a visualizer, that takes the output of this "stitcher" and shows it visually in a HTML form, this is what is linked below:
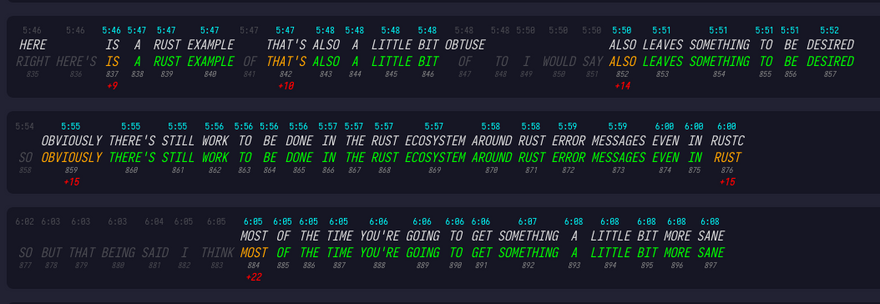
On one hand, the ~60% match rate is nothing to call home about. Trying to build a fully automated captioning system without further finetuning would yield rather unconvincing results.
On the other hand though, when we take a closer look, we realize that the accuracy of "regular" talk transcription is actually reasonably good!
Now, it is nigh impossible to compete with the tens of millions of people using Alexa or Google Home every day, or the multiple years worth of content uploaded to YouTube every hour — the voice data and resources that are at the disposal of Amazon, Google and the likes are astounding. So the fact that we could achieve decent transcription without mountains of data and datacenter-sized compute resources is already pretty amazing — but we also have at least one advantage over these megacorps... but well, let's not get ahead of ourselves.
Remember, this is the pre-trained generic out-of-the-box model that ships with DeepSpeech releases, let's see what possibilities can some customization unlock for us...
Further fine-tuning
Without wading too deep into how DeepSeech works, there are two main components: the main beam search decoder, a neural network that transcribes sounds into characters of an alphabet and constructs the output words alongside an (optional) external scorer that helps to augment the results. The scorer contains a language model (generated from a large collection of text from the target language) and helps "bias" towards word compositions that are more probable. Here's a simplified example of the concept:
NEWfollowed byYOLKis not really frequently used in the text corpus our scorer was built on. ButNEW+YORKis, and especially when followed byCITY. Our scorer will use this knowledge to influence the final result of the decoding accordingly.
There are, thus, two ways to improve transcription accuracy:
- improve the acoustic model — to transcribe the spoken audio more accurately, and
- improve the scorer — build a better language model to better bias towards more relevant word combinations
The first can be accomplished via fine-tuning, an exercise for after the proof-of-concept, but below we will be talking briefly about early results with the second approach.
We can generate a new language model for DeepSpeech using any text corpus — any sufficiently large body of target-language text will do. In a generic scenario, we would need to be mindful of overfitting, creating a model that is only any good predicting the data it has been trained on, but... well for timecoding, that is precisely what we need! We can generate a custom language model from the collected RustFest talk transcripts and see how it changes the equation:

Whoah, look at all that beautiful bright green! Of course the transcription is still not perfect, there are two main sources of error that remain still:
- Some of these are "mishearings" of the acoustic model, that cannot be corrected even with such an overfitted language model, but
- Some of these stem from the fact that human captioners take certain liberties when they transcribe a speaker: some of these are genuine and improve the brevity and/or clarity of the transcript, and occasionally these come from omissions (e.g. when a transcriber falls behind).
We will share some thoughts about how we plan to account for these issues going forward, but first, let's see what we can do with this data.
Using the DeepSpeech results
Okay, so DeepSpeech spit out some text & timings and we correlated this to the transcripts, what now? Taking over the world, of course!
For example, we can easily turn a time-coded transcript into subtitles!
We are currently in the process of publishing all previous RustFest recordings on our website and this allows us to provide subtitles for all talks, as well as a transcript. In fact, we can even allow the user to jump to parts of the video by clicking on the transcript — similarly how the visualizer allows for jumping to parts of the talk when clicking the. However all this is just the tip of the iceberg.
So far we have only used DeepSpeech on existing recordings, but DS is a streaming speech-to-text engine, it supports real-time inference! This means it's possible to do speech to text on the Waasabi backend and pipe the captions out in real time for any incoming video stream:
The above would allow low-budget or no-budget events (such as community meetups or similar) to provide completely automatic "best-effort" captions to any content using fine-tuned, custom models that fit their purpose, but this could even help events with human captioners improve their user experience, too! How?
We could turn the livestream's latency to our advantage! By having the human captioner in the "studio" (near-realtime access to conference feed) they would be "ahead" of the stream as they were transcribing it. Meanwhile, we would generate an automatic transcript as well, timecoded to the currently active live stream. By combining these two in the same way we have demonstrated above, and sending down the generated captions on a direct realtime channel to the clients (e.g. WebSockets), we could ensure the captions appear exactly when they were supposed to during the client's playback! No more spoilers!
Artisanal, small-batch, hand crafted machine learning
As we said before, it's impossible to compete with data, resources and sheer scale of Google and the likes as an idividual or small community. We ourselves have resorted to be using YouTube's captioning and transcript-auto-syncing (around which seemingly an entire cottage-industry of "how to download your YouTube subtitles" content producers has sprung up). We do have one advantage though: in the sea of all this content, YouTube remains generic, while we can differentiate and bias towards our own content.
As showcased before, a lot of the words the pre-trained (generic!) model missed — Rust, errors, compilation — were the topic, or even industry-specific ones. We can afford to bias our models towards these without having to worry about other users, other consumers. What's more, our own models, trained on historical Rust content may be used by other events: conferences, meetups, live streamers! Then, these content producers would reap the gains of this focus for their own content and audience, after which they, too, could contribute their own recordings, transcripts to be used to further fine-tune the model and contribute back to the "commons"!
So what's next?
We are coming away with really promising results from our research on this proof-of-concept and are eager to start the 'productization' process, to be able to use these techniques and technologies on our own upcoming events — and can't wait to see others test-drive and adopt them.
One of the first things on our list of "next steps" is creating a self-contained RTMP stream proxy, that event hosts could pipe their live studio directly into for real time deepspeech transcription. The tool would take care of pushing the transcribed speech content into Waasabi, as well as forwarding the studio content to its intended streaming destination (Mux, Peertube, or even any other destination outside of Waasabi).
Another very exciting feature we are looking into is in the front-end side: implementing crowd-sourced suggestions into the system. This would allow people watching the event live stream, replays or published recordings to suggest changes to the transcript in real time which could greatly improve the precision of transcripts. Since Waasabi provides instant replays for event attendees, making it possible to correct transcripts on the fly would provide a huge boost to the user experience of viewers joining in later on.
We are also currently experimenting with employing the precisely time-coded transcripts to automatically fine-tune the acoustic model. In theory, we could have DeepSpeech and some clever scripts identify parts of the document that the current model misses use the audio extracted for these sections and the transcript to propose targeted fine-tuning of the acoustic model. This would especially become interesting for speakers of various English accents to make the model more capable in detecting and transcribing non-vanilla English speakers.
Finally, we are also looking to working with other communities and content producers as early-adopters of this technology. We are also looking at adjacent content-producers, such as podcasts with a large archive to see if they can make use of this technique to augment their podcast archives and provide live transcription.
Let's stay in touch!
Thank you for your interest in this long report, and we'd like to thank Grant for the Web for funding this effort!
Follow our updates on Open Collective and Twitter. You will find all the source code on GitHub. You can ask questions and chat with us on Matrix.




Top comments (3)
Hey Flaki - nice write-up!
If you have words, media but no timings you can align (for free) using something like Gentle (English only). Then convert to a Hyperaudio Lite (MIT Licensed) based Interactive Transcript using our converter - source code here.
Alternatively you could take a look at our Wordpress plugin.
Thanks Mark! I didn't know about Kaldi/Gentle, looks like a really cool tool to generate more precise timings for the transcripts to feed back/retrain our models based on the media content, thank you for the tip (and the praise).
Yes, the plethora of timed transcript formats I found while checking out Hyperaudio was also super useful, so we don't reinvent the wheel but use one of those to create our generated transcripts.
Very well written and detailed blog post, thanks for publishing!