
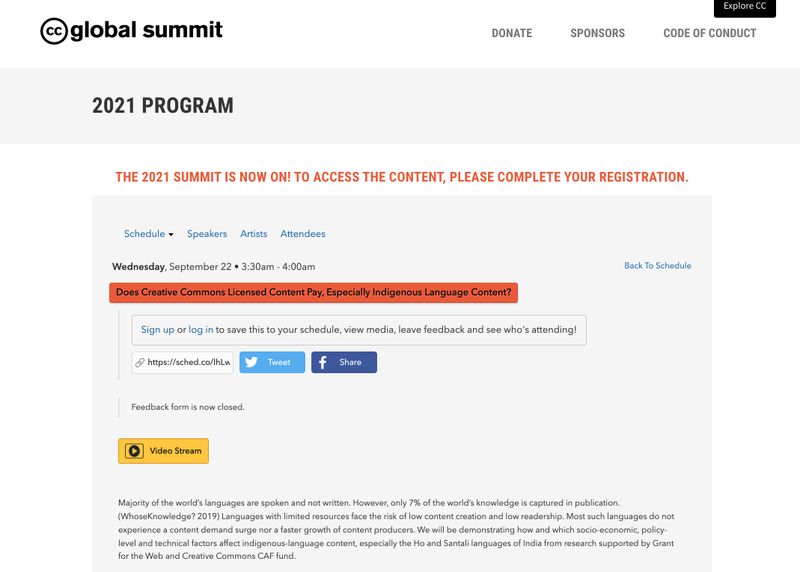
Screengrab of our Creative Commons Global Summit 2021 session: "Does Creative Commons Licensed Content Pay, Especially Indigenous Language Content?"
Project Update
As Distributed Ledger Technology (DLT) is gaining popularity in the larger web content sector, we have been studying what its expected impact would be for many indigenous communities in India. As we started working on the project to understand whether it would help promote open and distributed user freedom, and lead to a expansive access to information and fair content monetization. We focused on two Adivasi (indigenous) languages from India -- Ho and Santali for our work. We brought onboard two community members -- Ganesh Birua and Prasanta Hembram -- to lead the research on the web content ecosystems. Ganesh and Prasanta also happen to be content creators in Ho and Santali respectively. They both
created a long list of hypothesis by touch-basing the socioeconomic, educational, business and geopolitical issues related to their own languages. We conducted an online sprint to help ourselves with anticipation of content creators and created a list of "how might we..." questions. We also studied existing literature to check the hypothesis.
While most of our work happened online, Prasanta was able to meet leverage a cultural event that he attended to meet some of the Santali content creators. This was helpful to get some anecdotal insights. Similarly, Subhashish co-organized a small workshop along with the Birbasa student union where youth members of the union learned about building an audio pronunciation library using open-source tool Lingua Libre. This workshop also helped strengthen the collaboration with some content creators in Ho.
Currently we are conducting three sets of surveys (respondents can choose from English, Ho and Santali based on their fluence) to collect a range of anthropological, technical and other relevant details from Ho and Santali web content creators. While these surveys would help us understand nuances that are neither captured in existing literature or are being captured in a comprehensive manner, it would also help paint a picture of the web content ecosystem in both these language. We plan to interview some of the respondents to further investigate the hindrances in relation to the growth of web content in Ho and Santali, and the opportunities that they see in the horizon. As a final outcome of this work, we plan to summarize these inputs into a set of recommendations for the future of DLT-based content in both Ho and Santali language, and also in many other low-resource languages. We are also developing an open framework that decision makers of DLT-enabled content platforms can use to make informed decisions before launching DLT-driven web monetization systems.
Progress on objectives
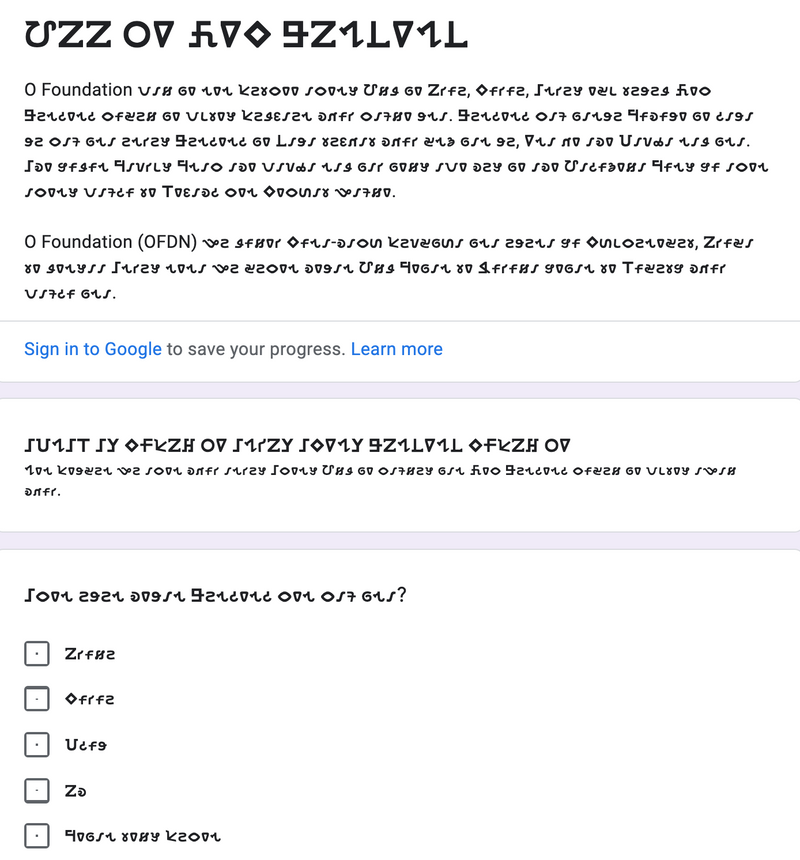
Screengrab of the questionnaire used for a survey in the Ho language
- Studied existing web content platforms that are in two indigenous languages (Ho and Santali) and/or are run by indigenous individuals/groups, their content dissemination process models, and their sustenance/business model.
- Investigated on speakers (end users/audience) of two low-resource languages that are predominantly spoken with a limited amount of content being documented in written format.
- We are in the process of investigating and documenting: a) demography and spectrum of the two target indigenous language speakers of India, b) web and multimedia content ecosystem, c) emerging trends, challenges and potential scopes, and a d) conceptual framework and model for enabling web monetization for citizen media.
- Built a conceptual framework that can help content creators better design content delivery models while keeping the freedom of content producers and content users in the core (as opposed to using personal data as a currency).
- While incorporating Web Monetization and Interledger Protocol in content models was in our original plan, we realized after further studying that it would be premature and the frameworks need to be used by decision makers of DLT-enabled platforms. So, we channeled our focus on building a robust framework and investigate further the web content ecosystem in both Ho and Santali.
- Also, we maximized the use of open licensing (Creative Commons), open source software and other open standards in our entire work. Our research is periodically documented publicly whereas some of the codes and data that we thought would be helpful for Ho and Santali web content creators are hosted on a repository on GitHub.
Key activities
- Design sprint: literature review, development of "how might we..." questions and preparation for Creative Commons Global Summit 2021 presentation
- Presented a session at the Creative Commons Global Summit 2021
- Participation by Prasanta Hembram at a Santali cultural event and documentation of anecdotal insights from content creators
- Organized a panel discussion at the United Nations Internet Governance Forum (IGF) titled "Building the wiki-way for low-resource languages
- Co-organizing a workshop on media creation in the Ho language by Subhashish P.
- Participation in the MozFest Trustworthy AI Working Groups program and development of openly-licensed (CC0 1.0 licensed) Natural Language Processing data in Ho and Santali.
- Submission to MozFest 2022: "Low-resource languages, and their open source AI/ML solutions through a radical empathy lens" (submission accepted)
Communications and marketing
- Periodic documentation in an open and public research page.
- We have mostly used telephonic and VOIP conversations for all remote communications.
- Session at online conference Creative Commons Global Summit 2021
- We have spent some funding in one physical workshop.
What’s next?
- Analysis of the ongoing surveys (respondents are web content creators in Ho and Santali), identification of a set of interviewees among the survey respondents and studying in detail the web content ecosystems.
- We plan to speak at MozFest 2022: "Low-resource languages, and their open source AI/ML solutions through a radical empathy lens" on March 9, 2022 and share the outcomes of our project
- We plan to publish the outcomes of our entire project by the end of March 2022 on the open research page.
- We are also applying to multiple conferences where we can present the final outcomes of our research and disseminate the same in the wider community.
What community support would benefit your project?
- We welcome any and all feedback or questions in the discussion page of our public research page. (one time sign up or log in with existing credentials required; comments without logging in will log IP addresses)
References
- Panigrahi S and Patnaik S (2021). Building the wiki-way for low-resource languages: Session Report. O Foundation. Bhubaneswar. United Nations Internet Governance Forum. DOI: http://dx.doi.org/10.17613/df9y-nz19 (accessed 19 December 2021). PDF
Attribution
- Cover image: Participants of the workshop on media creation in the Ho language. Image used with permission from Birbasa, Bhubaneswar, India.

Top comments (0)